

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 간편결제
- it #응집도 #결합도 #소프트웨어
- ETF
- openai
- 네이버
- 오블완
- 토스페이
- 결제취소
- clova
- sw
- OpenCV
- SQL
- 티스토리챌린지
- Ai
- 릿코드
- Node
- 코딩
- 웹훅
- certbot
- 프로그래머스
- 카카오페이
- 깃허브
- 결제
- 포트원
- OCR
- 데이터베이스 #백엔드 #데이터
- 백준
- 코딩테스트
- supabase
- 정렬
- Today
- Total
싱싱미역상태
구글과 네이버 본문
Google OCR 비교 과정 스토리
OCR을 회사에서 사용중인데 영어가 아닌 한글을 사용하는 경우가 생겼습니다. 따라서 기존에 사용하던 Google OCR을 사용했습니다. 하지만 결과값은 매우 처참했습니다.

테스트용 문구
해당 파일로 Google OCR을 돌려보니 아래와 같은 결과나 추출되었습니다.

다른 파일로도 테스트를 해봤지만 이상한 문자까지 같이 출력이 되었습니다. 따라서 Google OCR은 한글보다는 영어를 잘 인식한다는 개인적인 결론을 내렸고, 대안으로 Naver OCR을 테스트하기로 결정했습니다.
Naver OCR 결과
일단 결과적으로 Naver OCR은 성공적이 였습니다. 위와 같은 테스트 문구를 동일하게 출력하니 아래와 같은 결과가 나오게 되었습니다.

약간의 온점(.) 또는 띄워쓰기 같은 인식률은 떨어지지만, 한글에 있어서는 Google OCR보다는 인식률이 훨씬 좋다는 것을 느꼈습니다.
Naver OCR 구성
먼저 Naver의 OCR을 이용하기 위해서는 Naver Cloud Platform을 가입하고 사용 요청을 받아야 합니다. 이후 CLOVA OCR을 클릭해서 도메인을 생성해야합니다.


정보 입력 후, secret_key와 Invoke URL을 받을 수 있습니다. 하지만 사용 시에는 옵션 부분의 API Gateway 연동에서 API Gateway 자동 연동을 해서 APIGW Invoke URL을 받아야 합니다.


왜냐하면 기본적으로 API Gateway 자동 연동을 하지 않으면 http 형태로 되어있어 보안 처리 수준이 낮아 통신을 할 수 없기 때문입니다. 따라서 아래의 두개를 만들어야 합니다.
- secret_key
- APIGW Invoke URL
(1시간 삽질함 ㅎ..)

자세한 내용은 공식문서를 참고하시면 됩니다. 최종적으로는 API Gateway에 Product가 생성되어야 합니다.
이후에는 CLOVA OCR 요청 방식에는 3가지로 나누어지게 됩니다.
- General
- Template
- Document
저의 경우는 General이기 때문에 이와 관련한 요청파라미터와 응답 파라미터를 알아보겠습니다.
Naver CLOVA OCR 요청 파라미터
공식문서
요청헤더
요청헤더로는 2개를 반드시 넣어야 합니다.

General OCR Request
저의 경우는 General 요청과 application/json 형태로 보내야 했기 때문에 아래와 같은 필드를 사용했습니다.

여기서 주의깊게 봐야하는 것은 enableTableDetection는 Domain이 나오는 페이지에서 표 추출 여부를 활성화 시켜야 합니다. (만약 표 추출 여부를 true로 하면, 요금은 증가하게 됩니다.)
최종 application/json 요청예시
curl --location --request POST 'https://*****.apigw.ntruss.com/custom/v1/33675/8f694ccb00dbd8001e9b0fcbac****************/general' \
--header 'Content-Type: application/json' \
--header 'X-OCR-SECRET: {앱 등록 시 발급받은 Secret Key}' \
--data '{
"version": "V2",
"requestId": "1234",
"timestamp": "1722225600000",
"lang": "ko",
"images": [
{
"format": "jpg",
"name": "demo_2",
"url": "https://www.ncloud.com/file-img/vol02/000/614/********/********_0001.jpg"
}
],
"enableTableDetection": false
}'Naver CLOVA OCR 응답 파라미터
Naver의 OCR 응답은 매우 신기한 형태입니다. 일단 Google OCR의 경우 읽은 데이터를 합쳐서 전부 반환합니다. 따라서 따로 개발자가 쪼개진 데이터를 합칠 필요가 없습니다. 하지만 Naver OCR의 경우 x 축과 y축으로 분리한 상태로 데이터가 날라옵니다.

응답 데이터의 경우도 공식문서를 확인하면 파악할 수 있을 것 입니다. 저는 이 응답 데이터에서 fields와 같이 배열 형태로 오는 부분이 너무 신기했습니다.

boundingPoly vertices는 이미지 처리나 OCR(Optical Character Recognition) 과정에서 인식된 텍스트나 객체의 위치를 나타내는 경계 다각형의 꼭짓점 좌표들을 의미합니다. 이 값들은 이미지에서 특정 영역을 사각형이나 다각형 형태로 감싸는 선의 꼭짓점 좌표를 정의합니다.
쉽게 말해, OCR 시스템이 이미지에서 텍스트를 인식할 때, 해당 텍스트가 이미지 내에서 정확히 어디에 위치하는지를 알려주기 위해 boundingPoly (경계 다각형)를 사용합니다. 이 vertices는 이 경계 다각형의 꼭짓점의 좌표들이며, 일반적으로 사각형을 나타냅니다.
이 정보는 OCR 시스템이 이미지에서 인식한 텍스트가 정확히 어디에 위치하는지를 나타내는 데 사용되며, 텍스트의 경계 상자를 그리거나 특정 텍스트를 추출할 때 유용하게 사용됩니다.
시각적 표시 : 이미지에서 인식된 텍스트의 위치를 화면에 사각형으로 표시할 때 사용됩니다.
정확한 위치 확인 : 이미지 처리에서 텍스트가 정확히 어느 좌표에 위치하는지 알 수 있어, 후속 처리를 위한 정보를 제공합니다.
이 boundingPoly는 네 개 이상의 좌표를 가질 수도 있으며, 사각형이 아닌 복잡한 다각형으로 영역을 정의할 수도 있습니다.
따라서 fields 데이터를 열어보니 매우 많은 변수들이 구성되어 있었고, 각 변수 안에는 inferText와 다른 여러 변수들이 존재했습니다. 특히 vertices에는 x축과 y축으로 구분하는 변수가 매우 신기했습니다. 일단 결론적으로 쪼개진 데이터를 받기 위해서는 inferText를 반복문을 통해 합쳐서 반환하는 것입니다.
for i in response.json()['images'][0]['fields']:
text = i['inferText']
print(text)
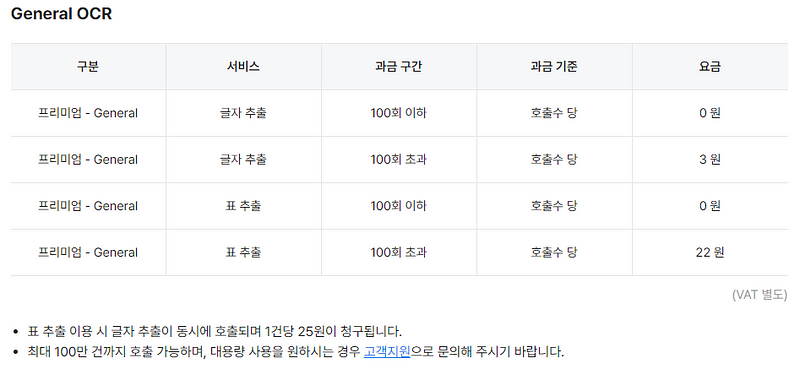
Naver CLOVA OCR 요금
100회까지는 무료이고 이후부터는 호출 수당 3원씩 추가됩니다. 만약 표를 추출한다면, 건당 3 + 22원으로 25원의 요금이 발생합니다. 또한 항상 표 추출로 인식하는 것이 아닌, 네이버가 판단하에 표 추출을 사용할 수도 있고 사용하지 않을 수도 있습니다.

'AI' 카테고리의 다른 글
| AICE (0) | 2025.04.22 |
|---|---|
| AI에서 LLM과 RAG의 관계 (1) | 2024.11.12 |
| OCR 성능을 위한 이미지 전처리 기술 (0) | 2024.11.08 |
| OpenAI Vision Token 개수 측정 (0) | 2024.11.05 |


